|
|
@@ -14,17 +14,43 @@ categories:
|
|
|
<span class="sub-tag">思考</span>
|
|
|
</div>
|
|
|
|
|
|
-## 引言
|
|
|
+最近看到一篇关于规范驱动开发的文章,作者指出一个有趣的现象:<span class="highlight-text">规范也是文档,而文档总是过时的</span>。
|
|
|
|
|
|
-最近看到一篇关于规范驱动开发的文章,作者指出一个有趣的现象:<span class="highlight-text">规范也是文档,而文档总是过时的</span>。
|
|
|
+这话说的没错,但我有一点点不同看法。规范驱动开发不是过时了,而是在AI时代<span class="gradient-text">进化了</span>。
|
|
|
|
|
|
-这话说的没错,但我有一点点不同看法。规范驱动开发不是过时了,而是在AI时代<span class="gradient-text">进化了</span>。或者说抛开AI至少在所有重要业务实现的前期阶段是必要的。
|
|
|
+不过,在讲怎么进化之前,我想先聊一个更底层的问题——<span class="highlight-text">为什么有时候规范是最新的,效率还是没提升?</span>
|
|
|
|
|
|
-## 一、文档驱动发展的历史脉络
|
|
|
+<!-- more -->
|
|
|
|
|
|
-### 早期困境:口头沟通的代价
|
|
|
+---
|
|
|
+
|
|
|
+## 一、先讲一个快手的案例
|
|
|
+
|
|
|
+前段时间快手技术团队发了一篇复盘,讲他们万人组织怎么用AI提升研发效能。看完我挺有感触的。
|
|
|
+
|
|
|
+他们2024年就全员推广AI编程工具,代码生成率干到了30%+,部分业务线甚至40%+。调研结果显示,开发同学主观体感效率提升了20-40%。
|
|
|
+
|
|
|
+看起来很美对吧?
|
|
|
+
|
|
|
+但看组织层面的数据:<span class="warning">需求交付周期基本没变,需求吞吐量也没明显提升。</span>
|
|
|
+
|
|
|
+快手把这个问题叫做<span class="gradient-text">"AI研发提效陷阱"</span>:
|
|
|
+
|
|
|
+```
|
|
|
+用AI开发工具 ≠ 个人提效 ≠ 组织提效
|
|
|
+```
|
|
|
+
|
|
|
+这事给我提了个醒。我们聊规范驱动开发,不能只聊"规范怎么保持最新",还得聊<span class="highlight-text">"规范怎么真正驱动交付"</span>。
|
|
|
+
|
|
|
+不然就像快手早期那样——工具用得很溜,但组织效率没动静。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## 二、文档驱动发展的历史脉络
|
|
|
|
|
|
-在软件工程的早期,项目主要依赖<span class="warning">口头沟通</span>和<span class="warning">个人记忆</span>。这种方式在小型团队里还行,但一旦团队扩大或人员流动,问题就暴露无遗:
|
|
|
+### 早期困境:口头沟通的代价
|
|
|
+
|
|
|
+在软件工程的早期,项目主要依赖<span class="warning">口头沟通</span>和<span class="warning">个人记忆</span>。这种方式在小型团队里还行,但一旦团队扩大或人员流动,问题就暴露无遗:
|
|
|
|
|
|
- 需求在传递中变形
|
|
|
- 知识随着人员离职而流失
|
|
|
@@ -33,137 +59,154 @@ categories:
|
|
|
|
|
|
### 文档驱动的出现
|
|
|
|
|
|
-为了解决这些问题,<span class="gradient-text">文档驱动开发</span>应运而生。它主要经历了几个阶段:
|
|
|
+为了解决这些问题,<span class="gradient-text">文档驱动开发</span>应运而生。它主要经历了几个阶段:
|
|
|
|
|
|
**1. 瀑布模型的PRD时代**
|
|
|
- 详细的PRD文档
|
|
|
- 完整的设计文档
|
|
|
- 严格的变更流程
|
|
|
-- 优点:标准化、可追溯
|
|
|
-- 缺点:僵化、响应慢
|
|
|
+- 优点:标准化、可追溯
|
|
|
+- 缺点:僵化、响应慢
|
|
|
|
|
|
**2. 敏捷时代的轻文档**
|
|
|
- 用户故事代替详细PRD
|
|
|
- 活跃的代码注释
|
|
|
- Wiki 风格的文档
|
|
|
-- 优点:灵活、快速迭代
|
|
|
-- 缺点:文档碎片化、维护困难
|
|
|
+- 优点:灵活、快速迭代
|
|
|
+- 缺点:文档碎片化、维护困难
|
|
|
|
|
|
### 文档驱动的核心价值
|
|
|
|
|
|
-不管哪个阶段,文档驱动都有其不可替代的价值:
|
|
|
+不管哪个阶段,文档驱动都有其不可替代的价值:
|
|
|
+
|
|
|
+- **知识沉淀**:团队知识不会随人员流动而丢失
|
|
|
+- **沟通效率**:减少反复沟通的成本
|
|
|
+- **质量保障**:明确的规范避免随意改动
|
|
|
+- **可追溯性**:决策过程有据可查
|
|
|
+- **新人友好**:降低入职门槛
|
|
|
|
|
|
-- **知识沉淀**:团队知识不会随人员流动而丢失
|
|
|
-- **沟通效率**:减少反复沟通的成本
|
|
|
-- **质量保障**:明确的规范避免随意改动
|
|
|
-- **可追溯性**:决策过程有据可查
|
|
|
-- **新人友好**:降低入职门槛
|
|
|
+但这里有个隐含假设:<span class="highlight-text">文档是给人看的,人会判断、会质疑、会沟通。</span>
|
|
|
+
|
|
|
+---
|
|
|
|
|
|
-## 二、AI时代的双重效应
|
|
|
+## 三、AI时代的三重效应
|
|
|
|
|
|
-### 负面影响:过时规范更危险
|
|
|
+### 第一重:过时规范更危险
|
|
|
|
|
|
-AI的出现,让文档过时的代价<span class="warning">成倍增加</span>。
|
|
|
+AI的出现,让文档过时的代价<span class="warning">成倍增加</span>。
|
|
|
|
|
|
-**人类工程师的行为模式**:
|
|
|
+**人类工程师的行为模式**:
|
|
|
- 读到过时文档 → 发现不对 → 会问"这文档好像有问题"
|
|
|
-- 有判断力,会质疑,会沟通
|
|
|
+- 有判断力,会质疑,会沟通
|
|
|
- 会用实际代码来验证文档
|
|
|
|
|
|
-**AI Agent的行为模式**:
|
|
|
+**AI Agent的行为模式**:
|
|
|
- 读到过时规范 → 严格执行
|
|
|
-- 缺乏质疑能力,假设规范总是正确的
|
|
|
+- 缺乏质疑能力,假设规范总是正确的
|
|
|
- 会按照过时的规范写出过时的代码
|
|
|
|
|
|
-<span class="important-note">问题就在这里:过时的设计文档只会误导碰巧读到它的人类工程师,而过时的规范会误导不知变通的AI Agent。</span>
|
|
|
+<span class="important-note">过时的设计文档只会误导碰巧读到它的人类工程师,而过时的规范会误导不知变通的AI Agent。</span>
|
|
|
+
|
|
|
+### 第二重:AI成为文档维护的解决方案
|
|
|
+
|
|
|
+但硬币的另一面是:<span class="gradient-text">AI恰恰是解决文档维护难题的最佳工具</span>。
|
|
|
+
|
|
|
+为什么这么说?因为文档维护的本质是:<span class="highlight-text">让文档与代码/现实保持同步</span>。
|
|
|
+
|
|
|
+而AI擅长的正是:
|
|
|
+- **理解代码**:分析代码结构和依赖
|
|
|
+- **生成文档**:根据代码自动生成文档
|
|
|
+- **检测差异**:对比文档和代码的差异
|
|
|
+- **自动更新**:根据代码变化更新文档
|
|
|
|
|
|
-AI Agent会自信满满地执行一个早已脱离实际的计划,根本不会发现哪里不对。
|
|
|
+### 第三重:个人提效≠组织提效(新增)
|
|
|
|
|
|
-### 正面影响:AI成为文档维护的解决方案
|
|
|
+这是快手案例给我最大的启发。
|
|
|
|
|
|
-但硬币的另一面是:<span class="gradient-text">AI恰恰是解决文档维护难题的最佳工具</span>。
|
|
|
+我们假设这样一个场景:
|
|
|
+- 规范是最新的,AI能自动维护
|
|
|
+- 每个开发同学都用AI写代码,个人效率提升30%
|
|
|
+- 但需求交付周期还是老样子
|
|
|
|
|
|
-为什么这么说?因为文档维护的本质是:<span class="highlight-text">让文档与代码/现实保持同步</span>。
|
|
|
+问题出在哪?
|
|
|
|
|
|
-而AI擅长的正是:
|
|
|
-- **理解代码**:分析代码结构和依赖
|
|
|
-- **生成文档**:根据代码自动生成文档
|
|
|
-- **检测差异**:对比文档和代码的差异
|
|
|
-- **自动更新**:根据代码变化更新文档
|
|
|
+<span class="highlight-text">规范只解决了"做什么"和"怎么做",但没解决"怎么协作交付"。</span>
|
|
|
|
|
|
-这正是文档维护需要的核心能力。
|
|
|
+快手早期的"智能化1.0"就是这个状态:推广AI编码工具、AI测试工具、AI CR工具,单点看每个工具都很好用,但端到端的流程没打通。
|
|
|
|
|
|
-## 三、规范驱动在AI时代的进化
|
|
|
+就像一条高速公路,每辆车的引擎都升级了,但收费站还是人工收费,整体通行速度能快吗?
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## 四、规范驱动在AI时代的进化
|
|
|
|
|
|
### 从静态文档到动态契约
|
|
|
|
|
|
-传统的规范驱动是这样的:
|
|
|
+传统的规范驱动是这样的:
|
|
|
```
|
|
|
-人类写规范 → 代码实现 → 规范过时 → 人类更新规范(如果记得的话)
|
|
|
+人类写规范 → 代码实现 → 规范过时 → 人类更新规范(如果记得的话)
|
|
|
```
|
|
|
|
|
|
-AI时代的规范驱动是这样的:
|
|
|
+AI时代的规范驱动应该是这样的:
|
|
|
```
|
|
|
人类描述意图 → AI草拟规范 → 人类审阅批准 → AI执行并更新规范
|
|
|
```
|
|
|
|
|
|
-<span class="gradient-text">关键变化:规范不再是静态的"圣旨",而是动态的"活文档"。</span>
|
|
|
+<span class="gradient-text">关键变化:规范不再是静态的"圣旨",而是动态的"活文档"。</span>
|
|
|
|
|
|
### 从单向传递到双向反馈
|
|
|
|
|
|
-**传统模式**:
|
|
|
+**传统模式**:
|
|
|
- 人类 → 规范 → 代码
|
|
|
-- 单向传递,信息单向流动
|
|
|
+- 单向传递,信息单向流动
|
|
|
|
|
|
-**AI模式**:
|
|
|
+**AI模式**:
|
|
|
- 人类 ↔ 规范 ↔ AI ↔ 代码
|
|
|
-- 双向反馈,信息循环流动
|
|
|
+- 双向反馈,信息循环流动
|
|
|
|
|
|
-当AI Agent在执行过程中发现:
|
|
|
+当AI Agent在执行过程中发现:
|
|
|
- API不支持规范中假设的方式
|
|
|
- 有现成的组件可以复用
|
|
|
- 某些方案不切实际
|
|
|
|
|
|
-它会<span class="highlight-text">自动更新规范</span>,而不是等人类发现问题。
|
|
|
+它会<span class="highlight-text">自动更新规范</span>,而不是等人类发现问题。
|
|
|
|
|
|
-这就像把任务交给优秀的初级工程师:
|
|
|
-- 发现问题自己更新工单
|
|
|
-- 不会等着你去发现问题
|
|
|
-- 会主动告诉你"之前的假设不对,我用另一种方式实现了"
|
|
|
+### 从单点规范到端到端流程(新增)
|
|
|
|
|
|
-### 从人工维护到自动同步
|
|
|
+这是结合快手经验的新认识。
|
|
|
|
|
|
-以前,文档更新完全依赖人工。工程师要:
|
|
|
-- 记得更新文档(总是忘记)
|
|
|
-- 抽时间更新文档(总被其他任务挤占)
|
|
|
-- 保持文档准确性(几乎不可能)
|
|
|
+以前我们理解的规范,主要是<span class="highlight-text">实现规范</span>——接口怎么设计、代码怎么写、测试怎么覆盖。
|
|
|
|
|
|
-现在,AI Agent在执行任务的同时,就能:
|
|
|
-- 检测到规范与实际实现的差异
|
|
|
-- 自动更新规范
|
|
|
-- 说明变更原因
|
|
|
+但AI时代,规范应该延伸到<span class="gradient-text">端到端的交付流程</span>:
|
|
|
|
|
|
-<span class="important-note">没有人需要专门记着去更新文档。因为更新文档本身就是AI工作的一部分。</span>
|
|
|
+- **需求分析规范**:AI怎么理解需求、怎么拆解任务
|
|
|
+- **协作规范**:AI Agent之间怎么分工、怎么交接
|
|
|
+- **质量门禁规范**:什么情况下可以进入下一阶段
|
|
|
+- **反馈规范**:AI怎么汇报进度、怎么暴露阻塞
|
|
|
|
|
|
-## 四、AI为什么能做得更好?
|
|
|
+快手"智能化2.0"的核心转变,就是从"推广AI工具"回归到"<span class="highlight-text">如何用AI提升需求端到端交付效率</span>"。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## 五、AI为什么能做得更好?
|
|
|
|
|
|
### 1. AI不知疲倦
|
|
|
|
|
|
-文档维护是<span class="warning">隐形工作</span>:
|
|
|
+文档维护是<span class="warning">隐形工作</span>:
|
|
|
- 不容易被看见
|
|
|
- 不容易被奖励
|
|
|
- 但需要持续投入
|
|
|
|
|
|
-人类会厌烦、会忘记、会偷懒。但AI不知疲倦,每次执行任务都会更新规范。
|
|
|
+人类会厌烦、会忘记、会偷懒。但AI不知疲倦,每次执行任务都会更新规范。
|
|
|
|
|
|
### 2. AI有上下文理解能力
|
|
|
|
|
|
-传统工具(如Swagger生成API文档)只能:
|
|
|
+传统工具(如Swagger生成API文档)只能:
|
|
|
- 基于代码注释生成
|
|
|
- 基于代码结构推断
|
|
|
- 缺乏业务上下文
|
|
|
|
|
|
-而AI能够:
|
|
|
+而AI能够:
|
|
|
- 理解代码的业务意图
|
|
|
- 分析代码的依赖关系
|
|
|
- 推断代码的设计决策
|
|
|
@@ -171,166 +214,187 @@ AI时代的规范驱动是这样的:
|
|
|
|
|
|
### 3. AI可以双向沟通
|
|
|
|
|
|
-传统工具是单向的:代码 → 文档。
|
|
|
+传统工具是单向的:代码 → 文档。
|
|
|
+
|
|
|
+但AI可以双向:
|
|
|
+- 代码 → 规范(从实现推断规范)
|
|
|
+- 规范 → 代码(从规范生成代码)
|
|
|
+- 规范 ↔ AI(在执行过程中持续对话)
|
|
|
|
|
|
-但AI可以双向:
|
|
|
-- 代码 → 规范(从实现推断规范)
|
|
|
-- 规范 → 代码(从规范生成代码)
|
|
|
-- 规范 ↔ AI(在执行过程中持续对话)
|
|
|
+这种双向沟通,让规范真正"活"起来。
|
|
|
|
|
|
-这种双向沟通,让规范真正"活"起来。
|
|
|
+### 4. AI可以建立反馈闭环(新增)
|
|
|
|
|
|
-### 4. AI有持续学习能力
|
|
|
+这是组织提效的关键。
|
|
|
|
|
|
-随着项目进展,AI可以学习:
|
|
|
-- 哪些规范模式有效
|
|
|
-- 哪些规范会误导AI
|
|
|
-- 哪些细节需要反馈
|
|
|
-- 哪些变更需要批准
|
|
|
+快手的经验表明,要建立三个层面的反馈:
|
|
|
|
|
|
-通过机器学习,整个系统会越来越智能。
|
|
|
+**第一层:规范与代码的反馈**
|
|
|
+- AI发现实现与规范不符 → 更新规范
|
|
|
|
|
|
-## 五、如何实现进化的规范驱动?
|
|
|
+**第二层:个人与任务的反馈**
|
|
|
+- AI完成子任务 → 更新整体进度 → 人类看到阻塞点
|
|
|
+
|
|
|
+**第三层:任务与组织的反馈**
|
|
|
+- 度量数据回流 → 识别瓶颈 → 调整规范
|
|
|
+
|
|
|
+<span class="highlight-text">只有这三层反馈都打通,个人效率才能传导到组织效率。</span>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## 六、如何实现进化的规范驱动?
|
|
|
|
|
|
### 1. 确立双向维护机制
|
|
|
|
|
|
-规范不只是人类写的,也不只是AI写的。双方都要维护。
|
|
|
+规范不只是人类写的,也不只是AI写的。双方都要维护。
|
|
|
|
|
|
-**人类负责**:
|
|
|
+**人类负责**:
|
|
|
- 设定目标和意图
|
|
|
- 审阅和批准AI草拟的规范
|
|
|
- 做架构决策和业务判断
|
|
|
- 处理异常情况和边界条件
|
|
|
|
|
|
-**AI负责**:
|
|
|
+**AI负责**:
|
|
|
- 根据意图草拟规范
|
|
|
- 拆解任务和子任务
|
|
|
- 执行代码实现
|
|
|
-- 更新规范(发现变化时)
|
|
|
+- 更新规范(发现变化时)
|
|
|
- 反馈执行中的发现
|
|
|
|
|
|
### 2. 把握反馈颗粒度
|
|
|
|
|
|
-这是最难的平衡:
|
|
|
+这是最难的平衡:
|
|
|
|
|
|
-**反馈太多**:
|
|
|
+**反馈太多**:
|
|
|
- 规范变成噪音
|
|
|
- 人类习惯性无视
|
|
|
- 失去规范的意义
|
|
|
|
|
|
-**反馈太少**:
|
|
|
+**反馈太少**:
|
|
|
- 人类失去控制感
|
|
|
- 不知道AI做了什么
|
|
|
- 无法及时纠正方向
|
|
|
|
|
|
-<span class="important-note">把握好颗粒度的关键:只反馈那些改变方向的决策。</span>
|
|
|
+<span class="important-note">把握好颗粒度的关键:只反馈那些改变方向的决策。</span>
|
|
|
|
|
|
-AI不需要汇报每行代码怎么写,只需要汇报:
|
|
|
-- 发现了现成的组件(不用新建)
|
|
|
-- API不支持某种方式(换了个实现)
|
|
|
-- 发现了未预料的限制(调整了方案)
|
|
|
+AI不需要汇报每行代码怎么写,只需要汇报:
|
|
|
+- 发现了现成的组件(不用新建)
|
|
|
+- API不支持某种方式(换了个实现)
|
|
|
+- 发现了未预料的限制(调整了方案)
|
|
|
|
|
|
### 3. 建立审查和批准机制
|
|
|
|
|
|
-让AI更新规范,需要两个前提:
|
|
|
+让AI更新规范,需要两个前提:
|
|
|
|
|
|
-<span class="highlight-text">信任</span> - 相信AI不会乱改规范
|
|
|
-<span class="highlight-text">机制</span> - 有审查机制,让人类能看到并批准/驳回AI的更新
|
|
|
+<span class="highlight-text">信任</span> - 相信AI不会乱改规范
|
|
|
+<span class="highlight-text">机制</span> - 有审查机制,让人类能看到并批准/驳回AI的更新
|
|
|
|
|
|
缺一不可。
|
|
|
|
|
|
-### 4. 设计增量更新流程
|
|
|
+### 4. 配套度量机制
|
|
|
|
|
|
-不是每次都从头重写规范,而是:
|
|
|
-- 标记哪些部分被更新了
|
|
|
-- 说明更新的原因
|
|
|
-- 提供变更的上下文
|
|
|
-- 让人类可以快速审阅
|
|
|
+这是快手给我的最大启发。
|
|
|
|
|
|
-## 六、一个实际例子
|
|
|
+规范驱动进化不能只凭感觉,得有数据验证。快手建立了三层度量:
|
|
|
|
|
|
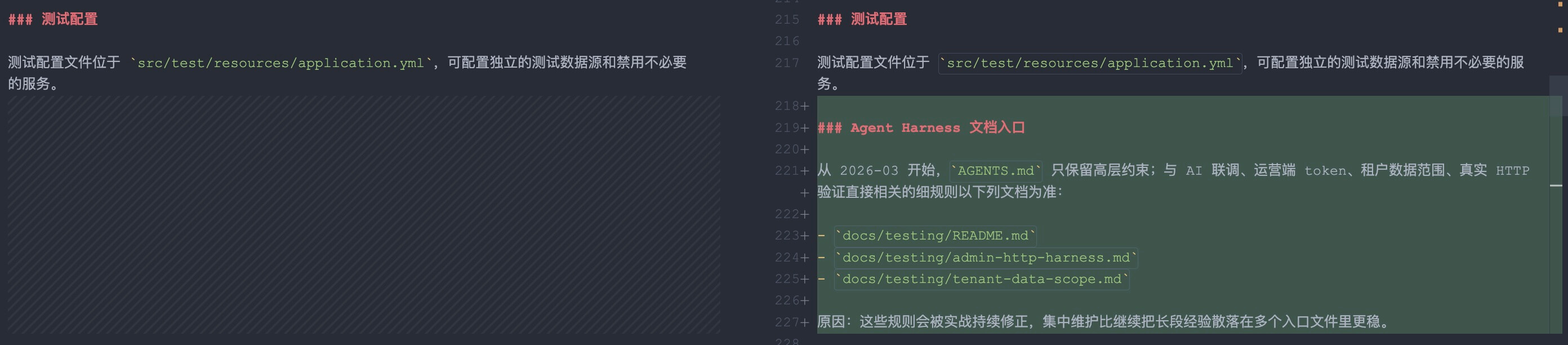
-来看一个我实际工作中的例子。当我让AI完成一个HTTP接口联调功能后,它自动更新了团队的开发规范文档:
|
|
|
+**过程指标**:AI代码生成率、AI CR采纳率
|
|
|
+**结果指标**:需求交付周期、需求吞吐量
|
|
|
+**健康度指标**:代码质量、线上稳定性
|
|
|
|
|
|
-{% asset_img ai-auto-update-spec.png AI自动更新规范文件的Git diff示例 %}
|
|
|
+<span class="highlight-text">关键是:不能只盯着过程指标。</span>
|
|
|
|
|
|
-上图展示了一个真实的场景:左侧是原有规范,右侧是AI自动补充的新内容。可以看到AI在`HTTP 自动化测试规范`部分新增了详细的测试要求,包括:
|
|
|
+AI代码生成率30%固然好看,但如果需求交付周期没变,说明规范只在编码环节生效,没有打通全流程。
|
|
|
|
|
|
-- **必须做1个真实接口自动验证** - 每次改动后自动执行业务接口测试
|
|
|
-- **默认验证用例(运营端)** - 提供具体的接口调用示例
|
|
|
-- **租户隔离对照测试(必做)** - 验证多租户隔离逻辑
|
|
|
-- **命令模板(可直接执行)** - 提供可执行的curl命令
|
|
|
-- **失败判定优先级** - 明确问题排查的顺序
|
|
|
+度量不是为了考核,是为了<span class="gradient-text">验证规范是否真的驱动了交付</span>。
|
|
|
|
|
|
-这个例子完美诠释了什么是"进化的规范驱动":**AI不仅执行代码,还主动更新配套文档,让规范始终保持与实现同步**。
|
|
|
+### 5. 设计增量更新流程
|
|
|
|
|
|
-再来看另一个更简单的例子。
|
|
|
-
|
|
|
-你写道:
|
|
|
+不是每次都从头重写规范,而是:
|
|
|
+- 标记哪些部分被更新了
|
|
|
+- 说明更新的原因
|
|
|
+- 提供变更的上下文
|
|
|
+- 让人类可以快速审阅
|
|
|
|
|
|
-> "在设置页面加个能跟随系统偏好的深色模式开关。"
|
|
|
+---
|
|
|
|
|
|
-协调Agent读取代码库,草拟一份规范:
|
|
|
+## 七、一个实际例子
|
|
|
|
|
|
-1. 添加开关组件
|
|
|
-2. 接入preference store
|
|
|
-3. 更新CSS变量
|
|
|
+来看一个我实际工作中的例子。当我让AI完成一个HTTP接口联调功能后,它自动更新了团队的开发规范文档:
|
|
|
|
|
|
-你扫了一眼,发现漏掉了"跨会话保存选择",于是补上一句。
|
|
|
+{% asset_img ai-auto-update-spec.png AI自动更新规范文件的Git diff示例 %}
|
|
|
|
|
|
-你点击批准。Agent开始干活。
|
|
|
+上图展示了一个真实的场景:左侧是原有规范,右侧是AI自动补充的新内容。可以看到AI在`HTTP 自动化测试规范`部分新增了详细的测试要求,包括:
|
|
|
|
|
|
-15分钟后,其中一个Agent更新了规范:
|
|
|
+- **必须做1个真实接口自动验证** - 每次改动后自动执行业务接口测试
|
|
|
+- **默认验证用例(运营端)** - 提供具体的接口调用示例
|
|
|
+- **租户隔离对照测试(必做)** - 验证多租户隔离逻辑
|
|
|
+- **命令模板(可直接执行)** - 提供可执行的curl命令
|
|
|
+- **失败判定优先级** - 明确问题排查的顺序
|
|
|
|
|
|
-> "在代码库里找到了现成的Theme Provider。已直接接入,未创建新store。"
|
|
|
+这个例子完美诠释了什么是"进化的规范驱动":<span class="highlight-text">AI不仅执行代码,还主动更新配套文档,让规范始终保持与实现同步</span>。
|
|
|
|
|
|
-你审查代码变更(已按Agent和任务清晰分组)。
|
|
|
+但更重要的是,我开始关注另一个指标:<span class="gradient-text">这个规范更新后,团队的整体交付节奏有没有变化?</span>
|
|
|
|
|
|
-现在,这份规范反映了实际做出来的东西,而不是最初计划的东西。
|
|
|
+不只是"规范是最新的",而是"最新的规范有没有让协作更顺畅"。
|
|
|
|
|
|
-<span class="gradient-text">最重要的是,没人需要专门记着去更新它。</span>
|
|
|
+---
|
|
|
|
|
|
-## 七、这种模式的推广
|
|
|
+## 八、这种模式的推广
|
|
|
|
|
|
-不只是代码规范,其他文档也可以这样进化:
|
|
|
+不只是代码规范,其他文档也可以这样进化:
|
|
|
|
|
|
### API文档
|
|
|
-- 传统:手动编写,过时即误导
|
|
|
-- 进化:AI解析代码和注释,自动生成和更新
|
|
|
+- 传统:手动编写,过时即误导
|
|
|
+- 进化:AI解析代码和注释,自动生成和更新
|
|
|
|
|
|
### 架构文档
|
|
|
-- 传统:画完就扔,没人更新
|
|
|
-- 进化:AI分析依赖关系,自动绘制和更新架构图
|
|
|
+- 传统:画完就扔,没人更新
|
|
|
+- 进化:AI分析依赖关系,自动绘制和更新架构图
|
|
|
|
|
|
-### 测试文档
|
|
|
-- 传统:手工编写,用例过时
|
|
|
-- 进化:AI执行测试,自动记录结果和覆盖率
|
|
|
+### 流程规范
|
|
|
+- 传统:写进Wiki,变成摆设
|
|
|
+- 进化:AI在执行中识别瓶颈,建议流程优化
|
|
|
|
|
|
-### 入职文档
|
|
|
-- 传统:一次性编写,快速过时
|
|
|
-- 进化:AI分析项目结构,动态生成入职指南
|
|
|
+<span class="highlight-text">流程规范特别值得强调。</span>快手的经验表明,AI时代的流程规范应该回答这些问题:
|
|
|
|
|
|
-## 八、结论
|
|
|
+- 需求怎么拆解成AI可执行的任务?
|
|
|
+- 多个AI Agent怎么协作?
|
|
|
+- 人类在什么节点介入?
|
|
|
+- 怎么度量端到端效率?
|
|
|
|
|
|
-文档维护是软件工程的老大难问题,AI时代这个问题变得更严重了。
|
|
|
+这些不是技术细节,是<span class="gradient-text">组织效能的基础设施</span>。
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## 九、结论
|
|
|
+
|
|
|
+文档维护是软件工程的老大难问题,AI时代这个问题变得更严重了。
|
|
|
|
|
|
但AI也带来了<span class="gradient-text">前所未有的机遇</span>。
|
|
|
|
|
|
-解决思路不是放弃文档驱动,而是让文档驱动<span class="highlight-text">进化</span>:
|
|
|
+解决思路不是放弃文档驱动,而是让文档驱动<span class="highlight-text">进化</span>:
|
|
|
|
|
|
- 从静态文档到动态契约
|
|
|
- 从人工维护到自动同步
|
|
|
- 从单向传递到双向反馈
|
|
|
-- 从一次性编写到持续演进
|
|
|
+- 从单点规范到端到端流程
|
|
|
+- 从主观感觉到数据度量
|
|
|
+
|
|
|
+<span class="gradient-text">规范不是人类单方面写的"圣旨",而是人类和AI共同维护的"活文档"。</span>
|
|
|
|
|
|
-<span class="gradient-text">规范不是人类单方面写的"圣旨",而是人类和AI共同维护的"活文档"。</span>
|
|
|
+但记住快手那个教训:<span class="highlight-text">规范保持最新只是第一步,让规范真正驱动端到端交付,才是最终目标。</span>
|
|
|
|
|
|
-这才是规范驱动开发在AI时代的正确打开方式。
|
|
|
+不然就会出现那种尴尬的局面——每个环节都很高效,但整体就是快不起来。
|
|
|
+
|
|
|
+---
|
|
|
|
|
|
## 参考
|
|
|
|
|
|
-原文: https://x.com/dotey/status/2026146560862474482
|
|
|
+原文:[https://x.com/dotey/status/2026146560862474482](https://x.com/dotey/status/2026146560862474482)
|
|
|
+
|
|
|
+快手研发范式复盘:[《快手万人组织 AI 研发范式 跃迁之路:从平台化、数字化、精益化到智能化》](https://mp.weixin.qq.com/s/Ejxpxn_MrJ1PDf-K38MpEg)
|
|
|
|
|
|
-相关阅读:
|
|
|
-- Multi-Agent Orchestration Patterns
|
|
|
-- Documentation as Code
|
|
|
-- Living Documentation
|
|
|
+相关阅读:
|
|
|
+- [Multi-Agent Orchestration Patterns](https://www.anthropic.com/research/multi-agent-orchestration)
|
|
|
+- [Documentation as Code](https://www.writethedocs.org/guide/docs-as-code/)
|
|
|
+- [Living Documentation](https://leanpub.com/livingdocumentation)
|


{kind=link}
{kind=link}
{kind=link}
